
Benchmarking your LLMs.
The systematic comparison engine for your AI stack.
Compare costs, track performance, and identify the most cost-efficient model for your use case.
Everything You Need
Compare and optimize LLM performance with data-driven insights
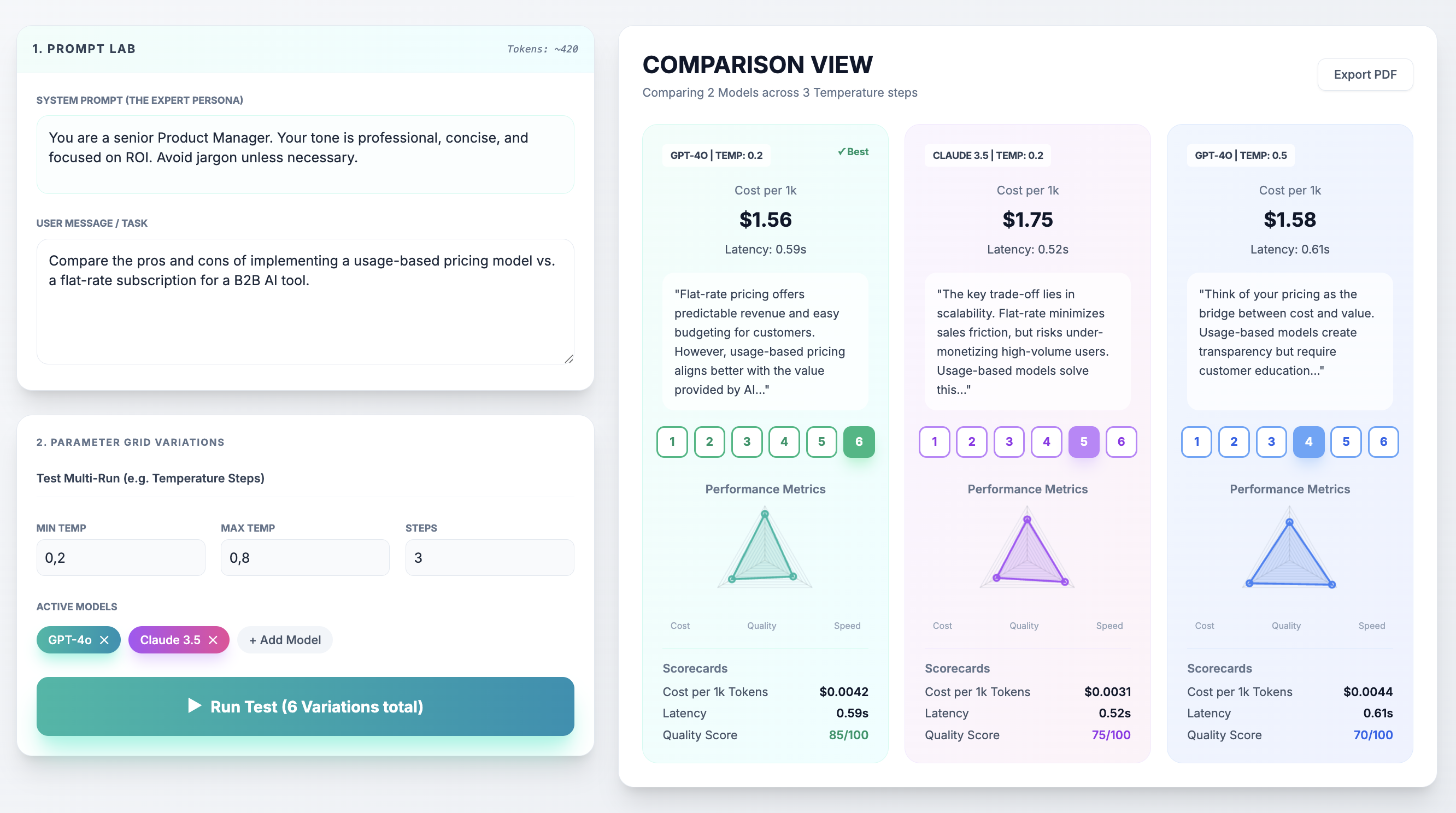
Multi-LLM Prompt Testing
Send one prompt to multiple models simultaneously. Compare GPT-4o, Claude 3.5 Sonnet, Llama-3-70B, and more.
- ✓ Single input, multiple outputs
- ✓ Real-time API integration
- ✓ BYOK (Bring Your Own Key)
Metrics & Performance
Automatic calculation of key metrics for data-driven decisions.
- ✓ Cost per 1k tokens
- ✓ Response latency tracking
- ✓ Visual scorecards & charts
Team Voting & Feedback NEW
Let your team vote on the best outputs and provide qualitative feedback.
- ✓ Thumbs up/down voting
- ✓ Comment & feedback system
- ✓ Aggregated team insights
From Prompt to Production in 4 Steps
Simple, powerful workflow for non-technical teams
Enter Your Prompt
Write your prompt once in a simple text field
Compare Results
View side-by-side outputs with metrics
Team Votes
Let your team rate and comment on outputs
Make Decisions
Choose the best model based on data
Perfect For
Product Managers
Validate AI features in minutes, not sprints. Test ideas without waiting for dev resources.
Product Owners
Control your COGS. Find the perfect balance between high-quality output and sustainable API margins.
Cross-Functional Teams
Bridge the gap between Engineering, Product, and QA with shared benchmarks and transparent voting.
Not sure if it's for you? See our use cases →
Ready to Optimize Your LLM Strategy?
Join the waitlist for early access to loopthink.ai MVP